Chapter 1: Q53E (page 45)
A mutual fund is a professionally managed investment scheme that pools money from many investors and invests in a variety of securities. Growth funds focus primarily on increasing the value of investments, whereas blended funds seek a balance between current income and growth. Here is data on the expense ratio (expenses as a % of assets, from www .morningstar.com) for samples of 20 large-cap balanced
funds and 20 large-cap growth funds (“largecap” refers to the sizes of companies in which the funds invest; the population sizes are 825 and 762,
respectively):
Bl 1.03 1.23 1.10 1.64 1.30
1.27 1.25 0.78 1.05 0.64
0.94 2.86 1.05 0.75 0.09
0.79 1.61 1.26 0.93 0.84
Gr 0.52 1.06 1.26 2.17 1.55
0.99 1.10 1.07 1.81 2.05
0.91 0.79 1.39 0.62 1.52
1.02 1.10 1.78 1.01 1.15
a. Calculate and compare the values of\(\bar x\),\(\tilde x\), and sfor the two types of funds.
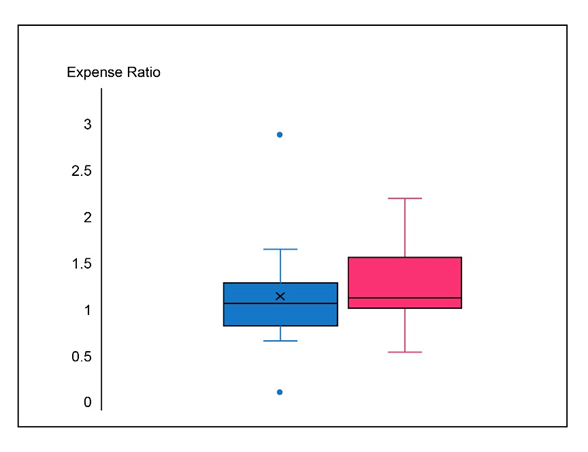
b. Construct a comparative boxplot for the two types of funds, and comment on interesting features.
Short Answer
a.
For BI, mean: 1.121, median:1.050 and standard deviation: 0.536.
For Gr, mean:1.244, median:1.100, and standard deviation:0.448.
b. A comparative boxplot is given as,
Step by step solution
Given information
The data on the expense ratio for samples of 20 large-cap balanced funds and 20 large-cap growth funds is provided.
Compute the sample mean
a.
Let x represents the large-cap balanced funds.
Let y represents the large-cap growth funds.
The sample mean for x is computed as,
\(\begin{aligned}\bar x &= \frac{{\sum {{x_i}} }}{n}\\ &= \frac{{1.03 + 1.23 + 1.10 + ... + 0.84}}{{20}}\\ &\approx 1.121\end{aligned}\)
Thus, the sample mean for x is 1.121.
The sample mean for y is computed as,
\(\begin{aligned}\bar y &= \frac{{\sum {{y_i}} }}{n}\\ &= \frac{{0.52 + 1.06 + 1.26 + ... + 1.15}}{{20}}\\ &\approx 1.244\end{aligned}\)
Thus, the sample mean for y is 1.244.
Compute the median
First arranging the data in ascending order,
For x,
0.09 | 1.05 |
0.64 | 1.1 |
0.75 | 1.23 |
0.78 | 1.25 |
0.79 | 1.26 |
0.84 | 1.27 |
0.93 | 1.3 |
0.94 | 1.61 |
1.03 | 1.64 |
1.05 | 2.86 |
For the even number of observations, the median value is computed as,
\(\begin{aligned}\tilde x &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{20}}{2}} \right)^{th}}and\;{\left( {\frac{{20}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {10} \right)^{th}}and\;{\left( {11} \right)^{th}}\;ordered\;values\\ &= \frac{{1.05 + 1.05}}{2}\\ &= 1.05\end{aligned}\)
Thus, the median value for x is 1.05.
The arranged data for y is given as,
0.52 | 1.1 |
0.62 | 1.15 |
0.79 | 1.26 |
0.91 | 1.39 |
0.99 | 1.52 |
1.01 | 1.55 |
1.02 | 1.78 |
1.06 | 1.81 |
1.07 | 2.05 |
1.1 | 2.17 |
For the even number of observations, the median value is computed as,
\(\begin{aligned}\tilde y &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{20}}{2}} \right)^{th}}and\;{\left( {\frac{{20}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {10} \right)^{th}}and\;{\left( {11} \right)^{th}}\;ordered\;values\\ &= \frac{{1.1 + 1.1}}{2}\\ &= 1.1\end{aligned}\)
Thus, the median value for y is 1.1.
Compute the sample standard deviation
The sample variance is given as,
\(\begin{aligned}{s^2} &= \frac{{\sum {{{\left( {{x_i} - \bar x} \right)}^2}} }}{{n - 1}}\\ &= \frac{{{S_{xx}}}}{{n - 1}}\end{aligned}\)
For x,
The calculations are represented as,
\({x_i}\) | \({x_i} - \bar x\) | \({\left( {{x_i} - \bar x} \right)^2}\) | |
1 | 1.03 | -0.0905 | 0.00819025 |
2 | 1.23 | 0.1095 | 0.01199025 |
3 | 1.1 | -0.0205 | 0.00042025 |
4 | 1.64 | 0.5195 | 0.26988025 |
5 | 1.3 | 0.1795 | 0.03222025 |
6 | 1.27 | 0.1495 | 0.02235025 |
7 | 1.25 | 0.1295 | 0.01677025 |
8 | 0.78 | -0.3405 | 0.11594025 |
9 | 1.05 | -0.0705 | 0.00497025 |
10 | 0.64 | -0.4805 | 0.23088025 |
11 | 0.94 | -0.1805 | 0.03258025 |
12 | 2.86 | 1.7395 | 3.02586025 |
13 | 1.05 | -0.0705 | 0.00497025 |
14 | 0.75 | -0.3705 | 0.13727025 |
15 | 0.09 | -1.0305 | 1.06193025 |
16 | 0.79 | -0.3305 | 0.10923025 |
17 | 1.61 | 0.4895 | 0.23961025 |
18 | 1.26 | 0.1395 | 0.01946025 |
19 | 0.93 | -0.1905 | 0.03629025 |
20 | 0.84 | -0.2805 | 0.07868025 |
Total | 5.459495 |
The sample variance is given as,
\(\begin{aligned}{s^2} &= \frac{{\sum {{{\left( {{x_i} - \bar x} \right)}^2}} }}{{n - 1}}\\ &= \frac{{5.4595}}{{20 - 1}}\\ &= 0.2873\end{aligned}\)
The standard deviation of x is computed as,
\(\begin{aligned}{s^2} &= \sqrt s \\ &= \sqrt {0.2873} \\ &= 0.536\end{aligned}\)
Therefore, the standard deviation of x is 0.536.
For y,
The calculations are represented as,
\({y_i}\) | \({y_i} - \bar y\) | \({\left( {{y_i} - \bar y} \right)^2}\) | |
1 | 0.52 | -0.7235 | 0.52345225 |
2 | 1.06 | -0.1835 | 0.03367225 |
3 | 1.26 | 0.0165 | 0.00027225 |
4 | 2.17 | 0.9265 | 0.85840225 |
5 | 1.55 | 0.3065 | 0.09394225 |
6 | 0.99 | -0.2535 | 0.06426225 |
7 | 1.1 | -0.1435 | 0.02059225 |
8 | 1.07 | -0.1735 | 0.03010225 |
9 | 1.81 | 0.5665 | 0.32092225 |
10 | 2.05 | 0.8065 | 0.65044225 |
11 | 0.91 | -0.3335 | 0.11122225 |
12 | 0.79 | -0.4535 | 0.20566225 |
13 | 1.39 | 0.1465 | 0.02146225 |
14 | 0.62 | -0.6235 | 0.38875225 |
15 | 1.52 | 0.2765 | 0.07645225 |
16 | 1.02 | -0.2235 | 0.04995225 |
17 | 1.1 | -0.1435 | 0.02059225 |
18 | 1.78 | 0.5365 | 0.28783225 |
19 | 1.01 | -0.2335 | 0.05452225 |
20 | 1.15 | -0.0935 | 0.00874225 |
Total | 3.821255 |
The sample variance is given as,
\(\begin{aligned}{s^2} &= \frac{{\sum {{{\left( {{y_i} - \bar y} \right)}^2}} }}{{n - 1}}\\ &= \frac{{3.8213}}{{20 - 1}}\\ &= 0.2011\end{aligned}\)
The standard deviation of y is computed as,
\(\begin{aligned}{s^2} &= \sqrt s \\ &= \sqrt {0.2011} \\ &= 0.448\end{aligned}\)
Therefore, the standard deviation of y is 0.448.
It can be observed that the mean and median values for variable y(large-cap growth funds)are greater than the mean and median of variable x(large-cap growth funds balanced funds). On the other hand, the standard deviation of y is less than the standard deviation of x.
Construct the comparative boxplot and comment on the features
b.
A comparative boxplot is a way to check the similarities and differences between two or more datasets.
Let x represents the large-cap balanced funds (BI).
Let y represent the large-cap growth funds(Gr).
Referring to part a,
For BI, mean: 1.121, median:1.050 and standard deviation: 0.536.
For Gr, mean:1.244, median:1.100, and standard deviation: 0.448.
The calculations for the five-number summary are as follows,
First arranging the data in ascending order,
B | G |
0.09 | 0.52 |
0.64 | 0.62 |
0.75 | 0.79 |
0.78 | 0.91 |
0.79 | 0.99 |
0.84 | 1.01 |
0.93 | 1.02 |
0.94 | 1.06 |
1.03 | 1.07 |
1.05 | 1.1 |
1.05 | 1.1 |
1.1 | 1.15 |
1.23 | 1.26 |
1.25 | 1.39 |
1.26 | 1.52 |
1.27 | 1.55 |
1.3 | 1.78 |
1.61 | 1.81 |
1.64 | 2.05 |
2.86 | 2.17 |
The lower fourth is computed by using the smallest half of the data,
\(\begin{aligned}lower\;fourth &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{10}}{2}} \right)^{th}}and\;{\left( {\frac{{10}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( 5 \right)^{th}}and\;{\left( 6 \right)^{th}}\;ordered\;values\\ &= \frac{{0.79 + 0.84}}{2}\\ &= 0.815\end{aligned}\)
This implies that the lower fourth is 0.815.
The upper fourth is computed by using the largest half of the data,
\(\begin{aligned}upper\;fourth &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{10}}{2}} \right)^{th}}and\;{\left( {\frac{{10}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( 5 \right)^{th}}and\;{\left( 6 \right)^{th}}\;ordered\;values\\ &= \frac{{1.26 + 1.27}}{2}\\ &= 1.265\end{aligned}\)
This implies that the upper fourth is 1.265.
The fourth spread is computed as,
\(\begin{aligned}{f_s} &= {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &= 1.265 - 0.815\\ &= 0.45\end{aligned}\)
Thus, the fourth spread is 0.45.
The five-number summary for BI,
1)smallest value is 0.09.
2)lower fourth is 0.815.
3) Median is 1.050.
4)upper fourth is 1.265.
5)largest value is 2.86.
For Gr,
The lower fourth is computed by using the smallest half of the data,
\(\begin{aligned}lower\;fourth &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{10}}{2}} \right)^{th}}and\;{\left( {\frac{{10}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( 5 \right)^{th}}and\;{\left( 6 \right)^{th}}\;ordered\;values\\ &= \frac{{0.99 + 1.01}}{2}\\ &= 1\end{aligned}\)
This implies that the lower fourth is 1.
The upper fourth is computed by using the largest half of the data,
\(\begin{aligned}upper\;fourth &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{10}}{2}} \right)^{th}}and\;{\left( {\frac{{10}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( 5 \right)^{th}}and\;{\left( 6 \right)^{th}}\;ordered\;values\\ &= \frac{{1.52 + 1.55}}{2}\\ &= 1.535\end{aligned}\)
This implies that the upper fourth is 1.535.
The fourth spread is computed as,
\(\begin{aligned}{f_s} &= {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &= 1.535 - 1\\ &= 0.535\end{aligned}\)
Thus, the fourth spread is 0.535.
The five-number summary for Gr,
1)smallest value is 0.52.
2)lower fourth is 1.
3) Median is 1.050.
4)upper fourth is 1.535.
5)largest value is 2.17.
The steps to construct a boxplot are as follows,
1)Compute the values of the five-number summary (smallest value, lower fourth, median, upper fourth, largest value).
2)Construct a line segment from the smallest value to the largest value of the dataset.
3) Construct a rectangular box from the lower fourth to the upper fourth and draw a line in the box at the median value.
The boxplot is represented as,
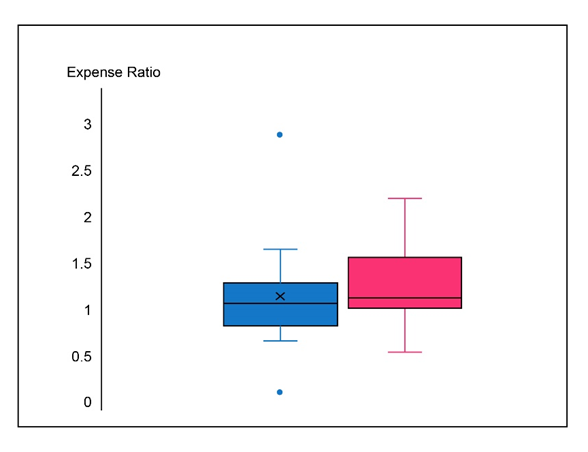
The blue boxplot represents Blended funds (BI) and the pink boxplot represents the Growth funds data.
The features that can be observed are as follows,
1)The ratios are quite similar for both the funds.
2)The distribution for the blended funds is substantially symmetric in the middle 50% but overall it is positively skewed. There is a substantial positive skewness in the middle 50% and an overall mild positive for the growth funds.
3)There is more variability in the Blended funds because of the presence of two outliers.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
