Chapter 1: Q48E (page 45)
Exercise 34 presented the following data on endotoxin concentration in settled dust both for a sample of urban homes and for a sample of farm homes:
U: 6.0 5.0 11.0 33.0 4.0 5.0 80.0 18.0 35.0 17.0 23.0
F: 4.0 14.0 11.0 9.0 9.0 8.0 4.0 20.0 5.0 8.9 21.0
9.2 3.0 2.0 0.3
a. Determine the value of the sample standard deviation for each sample, interpret these values, and then contrast variability in the two samples. (Hint:\(\sum {{x_i}} \)= 237.0 for the urban sample and =128.4 for the farm sample, and\(\sum {x_i^2} \)= 10,079 for the urban sample and 1617.94 for the farm sample.)
b. Compute the fourth spread for each sample and compare. Do the fourth spreads convey the same message about variability that the standard deviations do? Explain.
c. Construct a comparative boxplot (as did the cited paper)and compare and contrast the four samples.
Short Answer
a.
The sample standard deviation for urban homes is 22.3.
The sample standard deviation for the farm is 6.088.
b.
The fourth spread of x is 33.
The fourth spread of y is 7.
c. A comparative boxplot is represented as,

Step by step solution
Given information
The data on endotoxin concentration in settled dust both for a sample of urban homes and for a sample of farm homes are provided.
Computing the sample standard deviation
a.
Let x represents the concentration (EU/mg) in settled dust for one sample of urban homes.
Let y represent the concentration (EU/mg) in settled dust for another farm homes.
Referring to part a of Exercise 34,
The sample mean for one sample of urban homes is 21.5.
The sample mean for another sample is 8.6.
The sample standard deviation is computed as,
For x,
\(\begin{array}{c}{s_x} &=& \sqrt {\frac{{\sum {{{\left( {{x_i} - \bar x} \right)}^2}} }}{{{n_x} - 1}}} \\ &=& \sqrt {\frac{{{{\left( {6 - 21.5} \right)}^2} + {{\left( {5 - 21.5} \right)}^2} + ... + {{\left( {23 - 21.5} \right)}^2}}}{{11 - 1}}} \\ &=& 22.3\end{array}\)
For y,
\(\begin{array}{c}{s_y} &=& \sqrt {\frac{{\sum {{{\left( {{y_i} - \bar y} \right)}^2}} }}{{{n_y} - 1}}} \\ &=& \sqrt {\frac{{{{\left( {4 - 6.088} \right)}^2} + {{\left( {14 - 6.088} \right)}^2} + ... + {{\left( {0.3 - 6.088} \right)}^2}}}{{15 - 1}}} \\ &=& 6.088\end{array}\)
Therefore, the sample standard deviation for x and y are 22.3 and 6.088 respectively.
Computing the fourth spread
b.
The fourth spread is computed as,
\({f_s} = {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\)
Where, the upper fourth is the median value of the largest half and the lower fourth is the median value of the smallest half.
The number of observations for x is 11 (odd).
The number of observations for y is 15 (odd).
Arranging the data in ascending order,
x | y |
4 | 0.3 |
5 | 2 |
5 | 3 |
6 | 4 |
11 | 4 |
17 | 5 |
18 | 8 |
23 | 8.9 |
33 | 9 |
35 | 9 |
80 | 9.2 |
11 | |
14 | |
20 | |
21 |
For x,
\(\begin{array}{l}{n_{smallest}} &=& 5\\{n_{{\rm{largest}}}} &=& 5\end{array}\)
The lower fourth is computed as,
\(\begin{array}{c}\frac{{{n_{smallest}} + 1}}{2} &=& \frac{{5 + 1}}{2}\\ &=& {3^{rd}}value\end{array}\)
The 3rd value of the smallest half is 5.
This implies that the lower fourth is 5.
The upper fourth is computed as,
\(\begin{array}{c}\frac{{{n_{{\rm{largest}}}} + 1}}{2} &=& \frac{{5 + 1}}{2}\\ &=& {3^{rd}}value\end{array}\)
The 3rd value of the largest half is 33.
This implies that the upper fourth is 33.
The fourth spread for the chamber cooler is computed as,
\(\begin{array}{c}{f_s} &=& {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &=& 33 - 5\\ &=& 28\end{array}\)
Thus, the fourth spread of x is 28.
For y,
\(\begin{array}{l}{n_{smallest}} &=& 7\\{n_{{\rm{largest}}}} &=& 7\end{array}\)
The lower fourth is computed as,
\(\begin{array}{c}\frac{{{n_{smallest}} + 1}}{2} &=& \frac{{7 + 1}}{2}\\ &=& {4^{th}}value\end{array}\)
The 4th value of the smallest half is 4.
This implies that the lower fourth is 4.
The upper fourth is computed as,
\(\begin{array}{c}\frac{{{n_{{\rm{largest}}}} + 1}}{2} &=& \frac{{7 + 1}}{2}\\ &=& {4^{th}}value\end{array}\)
The 4th value of the largest half is 11.
This implies that the upper fourth is 11.
The fourth spread for y is computed as,
\(\begin{array}{c}{f_s} &=& {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &=& 11 - 4\\ &=& 7\end{array}\)
Thus, the fourth spread of y is 7.
Construction a comparative boxplot and compare the four samples
c.
Let p represents the concentration (EU/mg) in dust bag dust for one sample of urban homes.
Let q represent the concentration (EU/mg) in dust bag dust for another farm homes.
The data arranged in ascending order can be represented as,
x | y | p | q |
4 | 0.3 | 1 | 0.2 |
5 | 2 | 13 | 2 |
5 | 3 | 24 | 5 |
6 | 4 | 24 | 6 |
11 | 4 | 33 | 10 |
17 | 5 | 34 | 11 |
18 | 8 | 34 | 13 |
23 | 8.9 | 35 | 13 |
33 | 9 | 38 | 17 |
35 | 9 | 40 | 17 |
80 | 9.2 | 49 | 23 |
11 | 104 | 27 | |
14 | 28 | ||
20 | 35 | ||
21 | 64 |
Referring to part b of Exercise 48, and part b of Exercise 34.
For x,
The lower fourth is 5.
The upper fourth is 33.
The smallest value is 4.
The largest value is 80.
The sample median is 17.
For y,
The lower fourth is 4.
The upper fourth is 11.
The smallest value is 0.3.
The largest value is 21.
The sample median is 8.9.
For p,
The smallest value is 1.
The largest value is 104.
For the even number of observations, the median value is computed as,
\(\begin{array}{c}\tilde p &=& average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &=& average\;of\;{\left( {\frac{{12}}{2}} \right)^{th}}and\;{\left( {\frac{{12}}{2} + 1} \right)^{th}}\;ordered\;values\\ &=& average\;of\;{\left( 6 \right)^{th}}and\;{\left( 7 \right)^{th}}\;ordered\;values\\ &=& \frac{{34 + 34}}{2}\\ &=& 34\end{array}\)
Thus, the median value is 34.
For p,
\(\begin{array}{l}{n_{smallest}} &=& 3\\{n_{{\rm{largest}}}} &=& 3\end{array}\)
The lower fourth is 3rdvalue of the smallest half; that is, 24.
This implies that the lower fourth is 24.
The upper fourth is 3rd value of the largest half is 38.
This implies that the upper fourth is 38.
For q,
The smallest value is 0.2.
The largest value is 64.
For the odd number of observations, the median value is computed as,
\(\begin{array}{c}\tilde q &=& {\left( {\frac{{n + 1}}{2}} \right)^{th}}ordered\;value\\ &=& {\left( {\frac{{15 + 1}}{2}} \right)^{th}}ordered\;value\\ &=& {\left( 8 \right)^{th}}ordered\;value\end{array}\)
Thus, the median value of q is 13.
For q,
\(\begin{array}{l}{n_{smallest}} &=& 7\\{n_{{\rm{largest}}}} &=& 7\end{array}\)
The lower fourth is computed as,
\(\begin{array}{c}\frac{{{n_{smallest}} + 1}}{2} &=& \frac{{7 + 1}}{2}\\ &=& {4^{th}}value\end{array}\)
The 4th value of the smallest half is 6.
This implies that the lower fourth is 6.
The upper fourth is computed as,
\(\begin{array}{c}\frac{{{n_{{\rm{largest}}}} + 1}}{2} &=& \frac{{7 + 1}}{2}\\ &=& {4^{th}}value\end{array}\)
The 4th value of the largest half is 27.
This implies that the upper fourth is 27.
The steps to construct a boxplot are as follows,
1) Compute the values of the five-number summary (smallest value, lower fourth, median, upper fourth, largest value).
2) Construct a line segment from the smallest value to the largest value of the dataset.
3) Construct a rectangular box from the lower fourth to the upper fourth and draw a line in the box at the median value.
The boxplot is represented as,
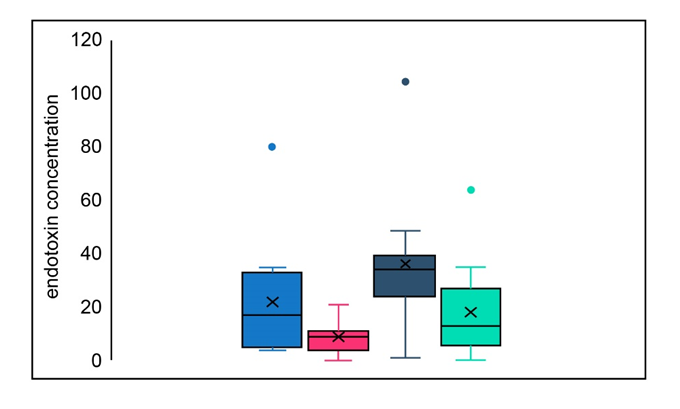
Where blue boxplot represents x, pink represents y, dark blue represents p and green represents q data.
The features that can be observed are,
1) The outliers can be observed insettled dust for one sample of urban homes, in dust bag dust for one sample of urban homes, and in dust bag dust for another farm homes.
2) For x, the distribution is approximately negatively skewed.
For y, the distribution is positively skewed.
For p, the distribution is positively skewed.
For q, the distribution is approximately negatively skewed
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
