Chapter 7: Q33E (page 302)
The article “Measuring and Understanding the Aging of Kraft Insulating Paper in Power Transformers” contained the following observations on degree of polymerization for paper specimens for which viscosity tim\({\rm{418 421 421 422 425 427 431 434 437 439 446 447 448 453 454 463 465}}\)es concentration fell in a certain middle range:
a. Construct a boxplot of the data and comment on any interesting features.
b. Is it plausible that the given sample observations were selected from a normal distribution?
c. Calculate a two-sided \({\rm{95\% }}\)confidence interval for true average degree of polymerization (as did the authors of the article). Does the interval suggest that \({\rm{440}}\) is a plausible value for true average degree of polymerization? What about \({\rm{450}}\)?
Short Answer
a. The distribution is skewed to the right (or positively skewed)
b. It is plausible that the given sample observations were selected from a normal distribution.
c. Boundaries of the confidence interval then become \((430.5073,446.0809)\)
Step by step solution
To Construct a boxplot
Given:
\(\begin{array}{l}{\rm{n = 17 }}\\{\rm{c = 95\% = 0}}{\rm{.95}}\end{array}\)
\(418,421,421,422,425,427,431,434,437,439,446,447,448,453,454,463,465\)
(a) The minimum is \(418{\rm{ }}.\)
Since the number of data values is odd, the median is the middle value of the sorted data set:
\({\rm{M = }}{{\rm{Q}}_{\rm{2}}}{\rm{ = 437}}\)
The first quartile is the median of the data values below the median
\({{\rm{Q}}_{\rm{1}}}{\rm{ = }}\frac{{{\rm{422 + 425}}}}{{\rm{2}}}{\rm{ = 423}}{\rm{.5}}\)
The third quartile is the median of the data values above the median
\({{\rm{Q}}_{\rm{3}}}{\rm{ = }}\frac{{{\rm{448 + 453}}}}{{\rm{2}}}{\rm{ = 450}}{\rm{.5}}\)
The maximum is \(465\) .
BOXPLOT
The whiskers of the boxplot are at the minimum and maximum value. The box starts at the first quartile, ends at the third quartile and has a vertical line at the median.
The first quartile is at \(25\% \)of the sorted data list, the median at \(50\% \)and the third quartile at \(75\% \).
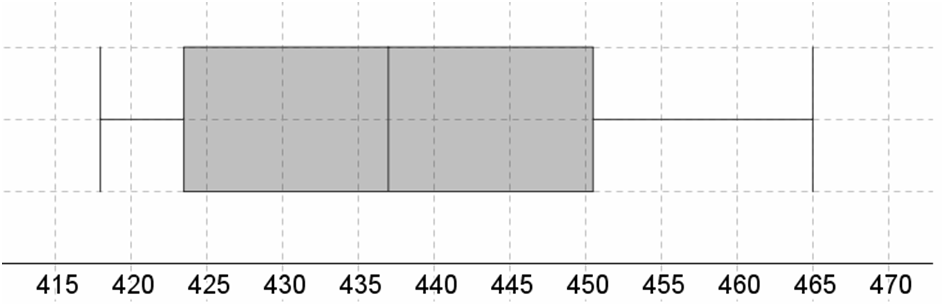
The distribution is skewed to the right (or positively skewed), because the box of the boxplot is to the left between the whiskers.
Hence Skewed to the right (or positively skewed)
To find the given sample observations were selected
(b)
NORMAL PROBABILITY PLOT
The data values are on the horizontal axis and the standardized normal scores are on the vertical axis.
If the data contains n data values, then the standardized normal scores are the z-scores in the normal probability table of the appendix corresponding to an area of \(\frac{{{\rm{j - 0}}{\rm{.5}}}}{{\rm{n}}}\) (or the closest area) with \({\rm{j\^I \{ 1,2,3, \ldots ,n\} }}\).
The smallest standardized score corresponds with the smallest data value, the second smallest standardized score corresponds with the second smallest data value, and so on.
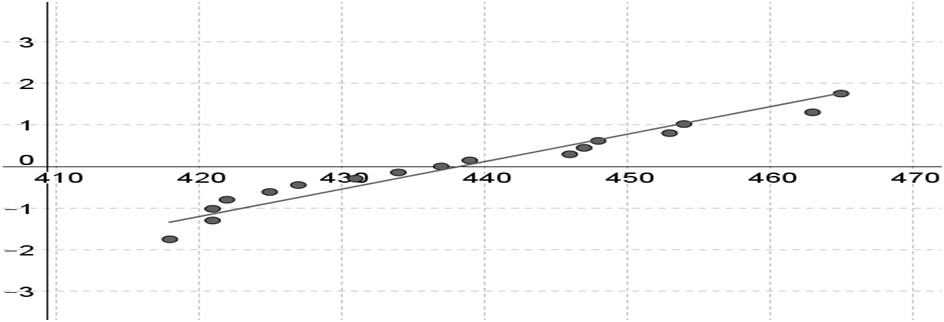
If the pattern in the normal probability does not contain strong curvature and is roughly linear, then it is plausible that the given observations originate from a normal distribution.
The pattern in the normal probability plot is roughly linear and does not contain strong curvature,
Thus we can conclude that it is plausible that the given sample observations were selected from a normal distribution.
To Calculate a two-sided \({\rm{95\% }}\)confidence interval
(c) The mean is the sum of all values divided by the number of values:
\({\rm{\bar x = }}\frac{{{\rm{418 + 421 + 421 + \ldots + 454 + 463 + 465}}}}{{{\rm{17}}}}{\rm{ = }}\frac{{{\rm{7451}}}}{{{\rm{17}}}}{\rm{\gg 438}}{\rm{.2941}}\)
The variance is the sum of squared deviations from the mean divided by $n-1$. The standard deviation is the square root of the variance:
\({\rm{s = }}\sqrt {\frac{{{{{\rm{(418 - 438}}{\rm{.2941)}}}^{\rm{2}}}{\rm{ + \ldots }}..{\rm{ + (465 - 438}}{\rm{.2941}}{{\rm{)}}^{\rm{2}}}}}{{{\rm{17 - 1}}}}} {\rm{\gg 15}}{\rm{.1442}}\)
Determine the t-value by looking in the row starting with degrees of freedom \({\rm{df = n - 1 = 17 - 1 = 16}}\) and in the column with \({\rm{\alpha = (1 - c)/2 = 0}}{\rm{.025}}\) in the table of the critical values for t distributions in the appendix:
\({{\rm{t}}_{{\rm{\alpha /2}}}}{\rm{ = 2}}{\rm{.120}}\)
The margin of error is then:
\({\rm{E = }}{{\rm{t}}_{{\rm{\alpha /2}}}}{\rm{ \times }}\frac{{\rm{s}}}{{\sqrt {\rm{n}} }}{\rm{ = 2}}{\rm{.120 \times }}\frac{{{\rm{15}}{\rm{.1442}}}}{{\sqrt {{\rm{17}}} }}{\rm{\gg 7}}{\rm{.7868}}\)
The boundaries of the confidence interval then become:
\(\begin{array}{l}{\rm{\bar x - E = 438}}{\rm{.2941 - 7}}{\rm{.7868 = 430}}{\rm{.5073}}\\{\rm{\bar x + E = 438}}{\rm{.2941 + 7}}{\rm{.7868 = 446}}{\rm{.080}}\end{array}\)
\(440\)is a plausible value for the true average degree of polymerization, because \(440\) lies between the boundaries of the confidence interval.
\(450\)is not a plausible value for the true average degree of polymerization, because \(450\) does not lie between the boundaries of the confidence interval.
Therefore
440: Plausible
450: Not plausible
Hence the boundaries of the confidence interval then become \((430.5073,446.0809)\)
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
