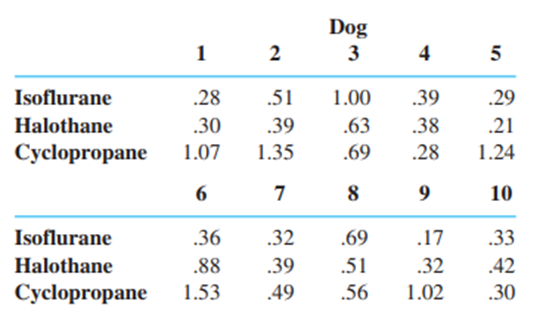
Chapter 15: Q14E (page 666)
The article "'Multimodal Versus Unimodal Instruction in a Complex Learning Environment" (J. of Experimental Educ., 2002: 215–239) described an experiment carried out to compare students' mastery of certain software learned in two different ways. The first learning method (multimodal instruction) involved the use of a visual manual. The second technique (unimodal instruction) employed a textual manual. Here are exam scores for the two groups at the end of the experiment (assignment to the groups was random):
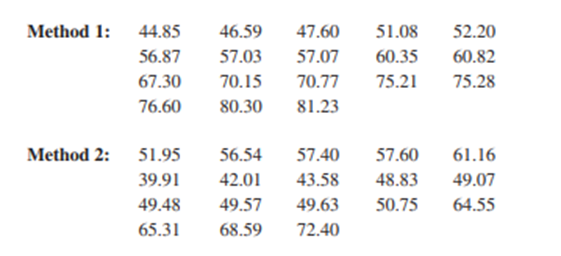
Does the data suggest that the true average score depends on which learning method is used?
Short Answer
Therefore,
There is sufficient evidence to support the claim that the true average score depends on which learning method is used.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!