Chapter 12: Q. 49 (page 792)
Marcella takes a shower every morning when she gets up. Her time in the shower varies according to a Normal distribution with mean minutes and standard deviation minutes.
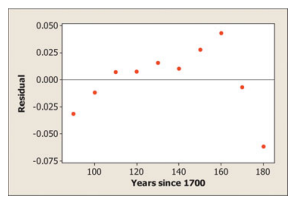
(a) If Marcella took a -minute shower, would it be classified as an outlier? Justify your answer.
(b) Suppose we choose days at random and record the length of Marcella’s shower each day. What’s the probability that her shower time is minutes or higher on at least of the days? Show your work.
(c) Find the probability that the mean length of her shower times on these 10 days exceeds minutes. Show your work
Short Answer
(a) If Marcella took a -minute shower, yes it is classified as an outlier.
(b) The probability is
(c) The probability that the mean length of her shower times is.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!