Chapter 2: Q117E (page 127)
Sanitation inspection of cruise ships. Refer to Exercise 2.81 (p. 111) and the data on the sanitation levels of passenger cruise ships.
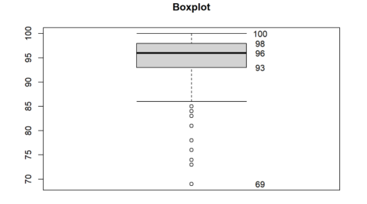
- Use the box plot method to detect any outliers in the data set.
- Use the z-score method to detect any outliers in the data set.
- Do the two methods agree? If not, explain why
Short Answer
105.5
This approach considers any point with a z-score more than 2 or less than -2 an outlier.
As a result, no outliers are discovered using the z-score approach.
Step by step solution
(a) Box plot method
We find the 5-point summary, as given below, and afterward calculate the IQR as well as outlier boundaries.
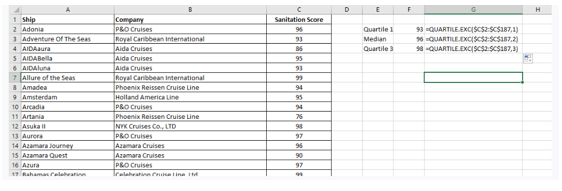
The five-point summary:
IQR=Q3-Q1
=98-93
=5
To find the outlier:
Thus, any worth less than 85.5 or more than 105.5 is an outlier.
As we can see, some points are less than 85.5 and thus are considered outliers.
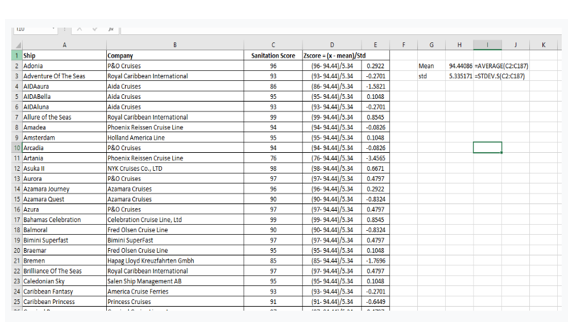
(b) z-score method
As illustrated, we compute the z-score for every observation.
This approach considers any point with a z-score more than 2 or less than -2 an outlier.
However, no outlier is discovered using this approach because no point has a z-score more than or even less than 2.
(c) Two methods
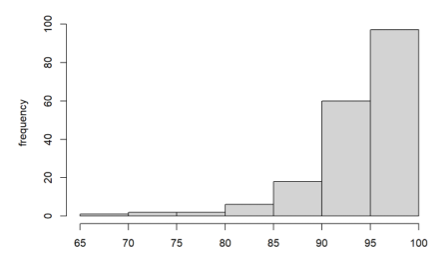
In the box plot approach, they only examine the centre 50% of the information to calculate the IQR, which is used as a measurement of the information's dispersion. When we plot the data as a histogram, we see that it is skewed to the left. As a result, employing the median as a central tendency measurement is more suitable in this circumstance.
One utilized the standard deviation and mean from the complete dataset in the z-score approach. Both are heavily influenced by outlier estimates and thus tend to distort the standard deviation and mean readings. As a result, no outliers are discovered using the z-score approach.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
