Chapter 2: Q115E (page 126)
Time in bankruptcy.Refer to the Financial Management(Spring 1995) study of 49 firms filing for prepackagedbankruptcies, Exercise 2.32 (p. 86). Recall that three typesof “prepack” firms exist: (1) those who hold no prefilingvote, (2) those who vote their preference for a joint solution;and (3) those who vote their preference for a prepack.
a.Construct a box plot for the time in bankruptcy (months) for each type of firm.
b.Find the median bankruptcy times for the three types.
c.How do the variabilities of the bankruptcy times compare for the three types?
d.The standard deviations of the bankruptcy times are 2.47 for “none,” 1.72 for “joint,” and 0.96 for “prepack.” Do the standard deviations agree with the interquartile ranges concerning the comparison of the variabilities of the bankruptcy times?
e.Is there evidence of outliers in any of the three distributions?
Short Answer
a.
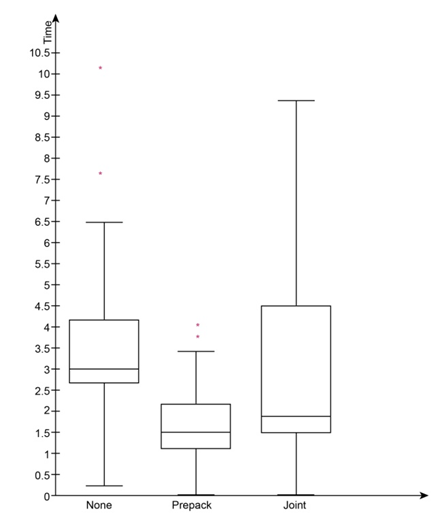
b. None = 3.2, Pre-pack = 1.4, Joint = 1.5
c. Firms with joint solutions have the most variability
d. Only for pre-pack, the standard deviation agrees with IQR
e. Firms with no prefiling and with a pre-pack have outliers
Step by step solution
Step-by-Step Solution Step 1: Constructing a box plot
Arranging the data in ascending order,

First, calculating the information needed to construct a box plot for no prefilling vote,
Second, calculating the data needed for a box plot of pre-pack votes
Third, computing the data for joint votes,
Finally, constructing the box plot,
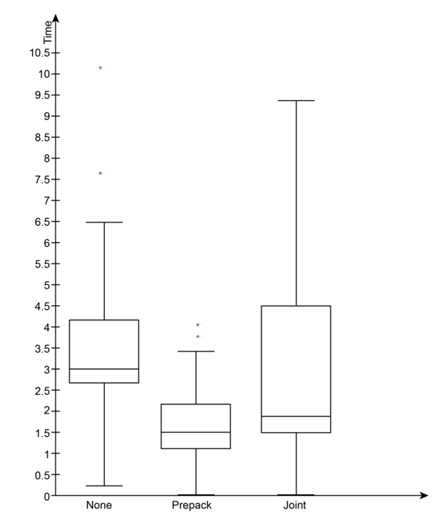
Finding the median bankruptcy time for all types of firms
Comparing the variabilities
Bankruptcy time for firms with a pre-pack is lower than the other two types of firms. The IQR is the highest for firms with a joint pack, followed by the firms with no prefiling.
Making a relation between the IQR and the standard deviations
The standard deviation and the IQR for the firms with no prefiling are 2.47 and 1.6, respectively. A very significant gap between the two numbers indicates the impact of outliers on the standard deviation.
The IQR (0.9) and the standard deviation (0.96) for pre-pack firms are almost the same. Whereas the IQR (3.1) and standard deviation (1.72) for the joint group are pretty far from each other, implying outliers' impact.
Identifying the outliers
Based on the boxplots created in step 1, we can say that there are 2 outliers (7.8, 10.1) in the no prefiling group. And 3 outliers (3.8, 4.1, 4.1) in the group of firms with pre-pack.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
