Chapter 1: Q2E (page 1)
The National Health and Nutrition Examination Survey (NHANES) collects demographic, socioeconomic, dietary, and health related information on an annual basis. Here is a sample of \({\rm{20}}\) observations on HDL cholesterol level \({\rm{(mg/dl)}}\) obtained from the \({\rm{2009 - 2010}}\) survey (HDL is “good” cholesterol; the higher its value, the lower the risk for heart disease):
\(\begin{array}{l}{\rm{35 49 52 54 65 51 51}}\\{\rm{47 86 36 46 33 39 45}}\\{\rm{39 63 95 35 30 48}}\end{array}\)
a. Calculate a point estimate of the population mean HDL cholesterol level.
b. Making no assumptions about the shape of the population distribution, calculate a point estimate of the value that separates the largest \({\rm{50\% }}\) of HDL levels from the smallest \({\rm{50\% }}\).
c. Calculate a point estimate of the population standard deviation.
d. An HDL level of at least \({\rm{60}}\) is considered desirable as it corresponds to a significantly lower risk of heart disease. Making no assumptions about the shape of the population distribution, estimate the proportion \({\rm{p}}\) of the population having an HDL level of at least \({\rm{60}}\).
Short Answer
(a) A point estimate of the population mean HDL cholesterol level is\({\rm{\bar x = 49}}{\rm{.95 mg/dl}}\).
(b) A point estimate of the value that separates the largest\({\rm{50\% }}\)of HDL levels from the smallest\({\rm{50\% }}\)is\({\rm{M = 47}}{\rm{.5 mg/dl}}\).
(c) A point estimate of the population standard deviation is\({\rm{s = 16}}{\rm{.8100 mg/dl}}\).
(d) The proportion \({\rm{p}}\) of the population having an HDL level of at least \({\rm{60}}\) is \({\rm{\hat p = 20\% }}\).
Step by step solution
Concept Introduction
The average of the given numbers is computed by dividing the total number of numbers by the sum of the given numbers.
The median is the middle number in a list of numbers that has been sorted ascending or descending, and it might be more descriptive of the data set than the average. When there are outliers in the series that could affect the average of the numbers, the median is sometimes utilised instead of the mean.
The standard deviation is a statistic that measures the amount of variation or dispersion in a set of numbers.
Point of Estimate (Mean)
(a)
The value of\({\rm{n}}\)is given as\({\rm{n = 20}}\).
The data provided is –
\(\begin{array}{l}{\rm{35 49 52 54 65 51 51 47 86 36}}\\{\rm{46 33 39 45 39 63 95 35 30 48}}\end{array}\)
A point estimate of the population mean is the sample mean.
The sample mean is the sum of all values divided by the number of values –
\(\begin{array}{c}{\rm{\bar x = }}\frac{{{\rm{35 + 49 + 52 + 54 + 65 + \ldots + 63 + 95 + 35 + 30 + 48}}}}{{{\rm{20}}}}\\{\rm{ = }}\frac{{{\rm{999}}}}{{{\rm{20}}}}\\{\rm{ = 49}}{\rm{.95}}\end{array}\)
Therefore, the value is obtained as \({\rm{\bar x = 49}}{\rm{.95 mg/dl}}\).
Step 3:Point of Estimate (Median)
(b)
The value of\({\rm{n}}\)is given as\({\rm{n = 20}}\).
The data provided is –
\(\begin{array}{l}{\rm{35 49 52 54 65 51 51 47 86 36}}\\{\rm{46 33 39 45 39 63 95 35 30 48}}\end{array}\)
The median separates the largest \({\rm{50\% }}\)from the smallest \({\rm{50\% }}\).
Apoint estimate that separates the largest \({\rm{50\% }}\)from the smallest \({\rm{50\% }}\)is the(sample)median.
Order the data values from smallest to largest –
\(\begin{array}{c}{\rm{30, 33, 35, 35, 36, 39, 39, 45, 46, 47,}}\\{\rm{48, 49, 51, 51, 52, 54, 63, 65, 86, 95}}\end{array}\)
Since the number of data values is even,the sample median is the average of the two middle values of the sorteddata set –
\(\begin{array}{c}{\rm{M = }}{{\rm{Q}}_{\rm{2}}}\\{\rm{ = }}\frac{{{\rm{47 + 48}}}}{{\rm{2}}}\\{\rm{ = 47}}{\rm{.5}}\end{array}\)
Therefore, the value is obtained as \({\rm{M = 47}}{\rm{.5 mg/dl}}\).
Step 4:Point of Estimate (Standard Deviation)
(c)
The value of\({\rm{n}}\)is given as\({\rm{n = 20}}\).
The data provided is –
\(\begin{array}{l}{\rm{35 49 52 54 65 51 51 47 86 36}}\\{\rm{46 33 39 45 39 63 95 35 30 48}}\end{array}\)
A point estimate of the population mean is the sample mean.
The sample mean is the sum of all values divided by the number of values –
\(\begin{array}{c}{\rm{\bar x = }}\frac{{{\rm{35 + 49 + 52 + 54 + 65 + \ldots + 63 + 95 + 35 + 30 + 48}}}}{{{\rm{20}}}}\\{\rm{ = }}\frac{{{\rm{999}}}}{{{\rm{20}}}}\\{\rm{ = 49}}{\rm{.95}}\end{array}\)
Apoint estimate of the population standard deviation is the sample standard deviation.
Create the following table –
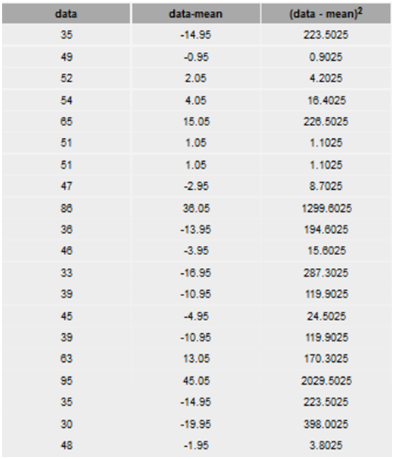
Find the sum of numbers in the last column to get –
\(\sum {{{{\rm{(}}{{\rm{x}}_{\rm{i}}}{\rm{ - \bar x)}}}^{\rm{2}}}{\rm{ = 5368}}{\rm{.95}}} \)
The variance is the sum of squared deviations from the mean divided by\({\rm{n - 1}}\). The standard deviation is thesquare root of the variance:
\(\begin{array}{c}{\rm{s = }}\sqrt {\frac{{{\rm{5368}}{\rm{.95}}}}{{{\rm{20 - 1}}}}} \\{\rm{ = }}\sqrt {\frac{{{\rm{5368}}{\rm{.95}}}}{{{\rm{19}}}}} \approx {\rm{16}}{\rm{.8100}}\end{array}\)
Therefore, the value is obtained as \({\rm{s = 16}}{\rm{.8100 mg/dl}}\).
Step 5:Point of Estimate (Proportion)
(d)
The value of\({\rm{n}}\)is given as\({\rm{n = 20}}\).
The data provided is –
\(\begin{array}{l}{\rm{35 49 52 54 65 51 51 47 86 36}}\\{\rm{46 33 39 45 39 63 95 35 30 48}}\end{array}\)
Apoint estimate of the population proportion is the sample proportion.
There are\({\rm{4}}\)data values in the sample that are greater than or equal to\({\rm{60}}\).
The sample proportion is the number of favourable outcomes divided by the sample size –
\(\begin{aligned} \hat p &= \frac{{\rm{4}}}{{{\rm{20}}}} = frac{{\rm{1}}}{{\rm{5}}}\\&= 0{\rm{.20}}\\ &= 20\%\end{aligned}\)
Therefore, the value is obtained as \({\rm{\hat p = 20\% }}\).
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
