Chapter 12: Q. 38 (page 788)
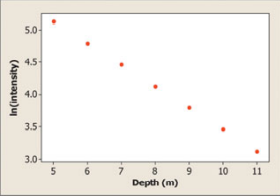
Some college students collected data on the intensity of light at various depths in a lake. Here are their data:
(a) Make a reasonably accurate scatterplot of the data by hand, using depth as the explanatory variable. Describe what you see.
(b) A scatterplot of the natural logarithm of light intensity versus depth is shown below. Based on this graph, explain why it would be reasonable to use an exponential model to describe the relationship between light intensity and depth.
Minitab output from a linear regression analysis on the transformed data is shown below
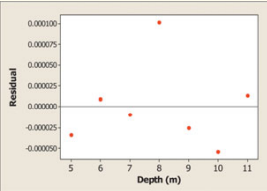
(c) Give the equation of the least-squares regression line. Be sure to define any variables you use.
(d) Use your model to predict the light intensity at a depth of meters. The actual light intensity reading at that depth was lumens. Does this surprise you? Explain
Short Answer
(a) The scatter plot is Negative, Curved, and Strong.
(b) It is reasonable to use the exponential model.
(c) The equation is .
(d) The light intensity at a depth of meters is and yes, it is surprising.
Step by step solution
Part(a) Step 1: Given Information
Part(a) Step 2: Explanation
The scatter plot of the data is:
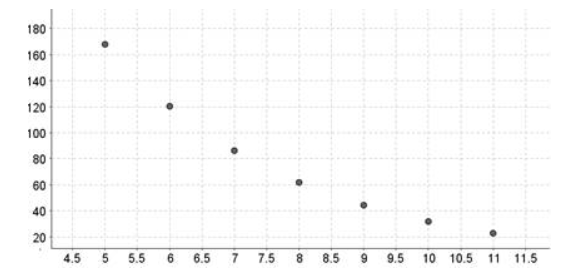
As a result, we can see from the scatterplot that,
Because the scatterplot slopes downhill, the direction is negative.
Because the points do not lie in a straight line, the shape is curved.
Strength: Strong because all points in the same pattern are relatively near together.
Part(b) Step 1: Given Information
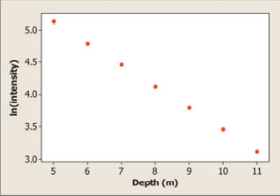
Part(b) Step 2: Explanation
The values for light intensity and depth are now provided in the question. Because the corresponding scatterplot exhibits a broadly linear pattern with no apparent strong outliers, we can infer that using an exponential model to represent the relationship between light intensity and depth would be plausible.
Part(c) Step 1: Given Information
Minitab output from a linear regression analysis on the transformed data is shown below.
Part(c) Step 2: Explanation
Now, represents depth and represents light intensity. As a result, the transformation is , which is the natural logarithm of the light intensity.
As we already know, the regression line's general equation is as follows:
role="math" localid="1652851293597"
The slope and constant in the computer output are as follows:
As a result, the regression line looks like this:
role="math" localid="1652851670453"
Part(d) Step 1: Given Information
Minitab output from a linear regression analysis on the transformed data is shown below.
Part(d) Step 2: Explanation
The regression line is
Calculating the equation as:
The residual is:
role="math" localid="1652851853646"
We are surprised by the outcome because the residual is more than .
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!