Chapter 12: Q170SE (page 816)
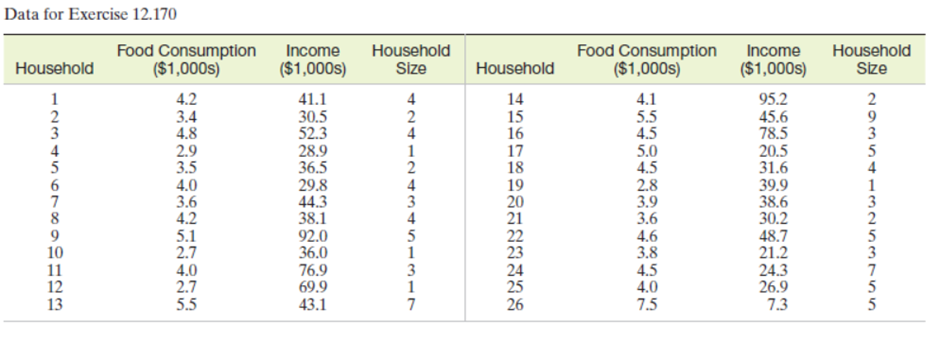
Question: Household food consumption. The data in the table below were collected for a random sample of 26 households in Washington, D.C. An economist wants to relate household food consumption, y, to household income, x1, and household size, x2, with the first-order model.
- Fit the model to the data. Do you detect any signs of multicollinearity in the data? Explain.
- Is there visual evidence (from a residual plot) that a second-order model may be more appropriate for predicting household food consumption? Explain.
- Comment on the assumption of constant error variance, using a residual plot. Does it appear to be satisfied?
- Are there any outliers in the data? If so, identify them.
- Based on a graph of the residuals, does the assumption of normal errors appear to be reasonably satisfied? Explain.
Short Answer
Answers
- To detect the sign of multicollinearity, it can be seen that the sign of the household’s income is negative but logically, the household’s consumption would increase with an increase in income. This might indicate the existence of multicollinearity.
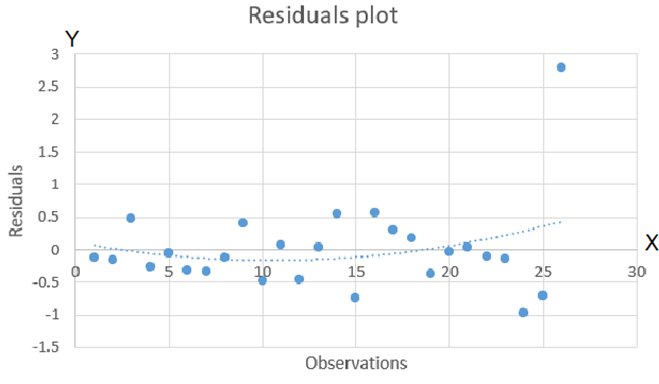
- From the residual plot, it can be seen that the second-order model is more appropriate for the data.
- The error variance from the residual plot does not look constant as the error terms are closer for the early observation while for the later observations, the spread in error terms increases.
- Observation 26 is an outlier as the residual value for the observation was 2.789.
- The assumption of normal errors is not satisfied here as the error variance from the graph is visible that is not constant.
Step by step solution
Given information
The number of observations is 26 households and the first order model is given as.
Model fitting
a.
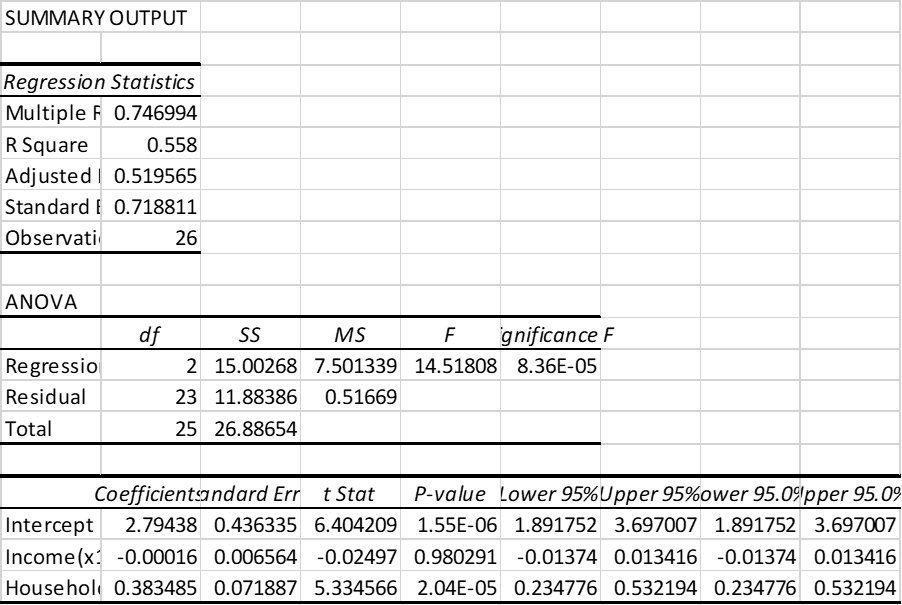
Given in the question is data of 26 household regarding their food consumption, y, to household income, and household size. The excel summary output is attached below. To detect the sign of multicollinearity, it can be seen that the sign of the household’s income is negative but logically, the household’s consumption would increase with an increase in income. This might indicate that existence of multicollinearity.
The model can be fitted using excel function data analysis. The values of y and ,x1 and x2 can be taken from the excel table and the regression model can be fitted using data analysis function in the data tab in the excel. This function automatically gives summary output of the model after getting the data about dependent, y, and independent variables, x1 and x2 .
For the anova table we need to calculate the mean if the independent variable and then calculate the SSR, SSE, and SST, after that one need to calculate the degrees of freedom and the mean squares and the F.
The SSR is calculated by using, and the SSE is calculated by squaring each term and adding them all. The SST is the sum of SSR and SSE. The MS regression is calculated by dividing SST by degrees of regression and similarly the MS residual is calculated by dividing SSE by degrees of residual and F is calculated by dividing MS regression by MS residual.
The coefficients of x is calculated by using this formula: whereas the coefficient of intercept is calculated by .
Thestandard error is calculated bydividingthe standard deviation by the sample size's square root.
The excel summary input is attached here.
Residual plot
b.
The process to drawn the residual plot is given as follows:
- Mean E = 0 - First, we demonstrate how a residual plot can detect a model in which the hypothesized relationship between E(y) and an independent variable x is mis specified. The assumption of mean error of 0 is violated in these types of models.
- Constant Error Variance-Residual plots can also be used to detect violations of the assumption of constant error variance.
- Errors Normally Distributed- Several graphical methods are available for assessing whether the random error e has an approximate normal distribution. If the assumption of normally distributed errors is satisfied, then we expect approximately 95% of the residuals to fall within 2 standard deviations of the mean of 0, and almost all of the residuals to lie within 3 standard deviations of the mean of 0.
- Errors Independent- The assumption of independent errors is violated when successive errors are correlated.
From the residual plot, it can be seen that second-order model is more appropriate for the data.
The graph can be drawn by plotting the residual values which are calculated by on the y -axis and putting the no of observations on the x-axis. After plotting the individual combinations, a line can be drawn to reflect the relationship between the two parameters.
Constant error variance assumption
c.
The error variance from the residual plot does not look constant as the error terms are closer for the early observation while for the later observations, the spread in error terms increases.
Outlier
d.
Observation 26 is an outlier as the residual value for the observation was 2.789 and from the graph also it is visible that there is an outlier.
Assumption of normal errors
The assumption of normally distributed errors is satisfied, then we expect approximately 95% of the residuals to fall within 2 standard deviations of the mean of 0, and almost all of the residuals to lie within 3 standard deviations of the mean of 0.
Here the assumption of normal errors is not satisfied here as the error variance from the graph is visible that is not constant. Some residual value observations are close to the regression line indicating small variance. However, some values are far from the regression line indicating a large variance between the y values and regressed y-values. This indicates that the error variance is not the same.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!