Chapter 6: Q9E (page 262)
Each of 150 newly manufactured items is examined and the number of scratches per item is recorded (the items are supposed to be free of scratches), yielding the following data:
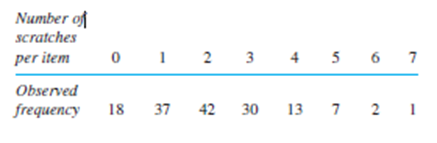
Assume that X has a Poisson distribution with parameter \({\bf{\mu }}.\)and that X represents the number of scratches on a randomly picked item.
a. Calculate the estimate for the data using an unbiased \({\bf{\mu }}.\)estimator. (Hint: for X Poisson, \({\rm{E(X) = \mu }}\) ,therefore \({\rm{E(\bar X) = ?)}}\)
c. What is your estimator's standard deviation (standard error)? Calculate the standard error estimate. (Hint: \({\rm{\sigma }}_{\rm{X}}^{\rm{2}}{\rm{ = \mu }}\), \({\rm{X}}\))
Short Answer
(a) The number of scratches per item and the observed frequency is \({\rm{2}}{\rm{.11}}\)
(b) The estimated standard error is \({\rm{0}}{\rm{.119}}{\rm{.}}\)
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
