Chapter 1: Q 59E (page 46)
Blood cocaine concentration (mg/L) was determined both for a sample of individuals who had died from cocaine-induced excited delirium (ED) and for a sample of those who had died from a cocaine overdose without excited delirium; survival time for people in both groups was at most 6 hours. The accompanying data was read from a comparative boxplot in the article “Fatal Excited Delirium Following Cocaine Use” (J.
of Forensic Sciences, 1997: 25–31).
ED0 0 0 0 .1 .1 .1 .1 .2 .2 .3 .3
.3 .4 .5 .7 .8 1.0 1.5 2.7 2.8
3.5 4.0 8.9 9.2 11.7 21.0
Non-ED0 0 0 0 0 .1 .1 .1 .1 .2 .2 .2
.3 .3 .3 .4 .5 .5 .6 .8 .9 1.0
1.2 1.4 1.5 1.7 2.0 3.2 3.5 4.1
4.3 4.8 5.0 5.6 5.9 6.0 6.4 7.9
8.3 8.7 9.1 9.6 9.9 11.0 11.5
12.2 12.7 14.0 16.6 17.8
a. Determine the medians, fourths, and fourth spreads for the two samples.
b. Are there any outliers in either sample? Any extreme outliers?
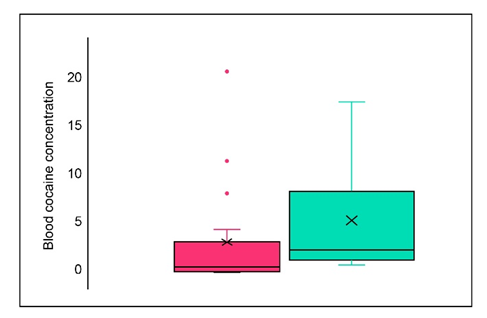
c. Construct a comparative boxplot, and use it as a basis for comparing and contrasting the ED and non-ED samples.
Short Answer
a. For ED,
The median value is 0.4.
The lower fourth is 0.1.
The Upper fourth is 2.8.
The fourth spread is 2.7.
For non-ED,
The median value is 1.6.
The lower fourth is 0.3.
The Upper fourth is 7.9.
The fourth spread is 7.6.
b. For ED,
The outliers are 8.9, 9.2,11.7 and 21.
The extreme outliers are 11.7 and 21.
For non-ED,
There are no outliers.
c. The box plot is represented as,
Step by step solution
Given information
The data for the individuals who had diet from cocaine-induced excited delirium (ED) and those who had died from a cocaine overdose without excited delirium is provided.
The sample size for ED samples is 27.
The sample size for non-ED samples is 50.
Computing the median
Let x represents the ED samples.
Let y represent the non-ED samples.
a.
The data is arranged in ascending order.
For x,
For the odd number of observations, the median value is computed as,
\(\begin{aligned}\tilde x &= {\left( {\frac{{n + 1}}{2}} \right)^{th}}ordered\;value\\ &= {\left( {\frac{{27 + 1}}{2}} \right)^{th}}ordered\;value\\ &= {\left( {14} \right)^{th}}ordered\;value\end{aligned}\)
Thus, the median value of x is 0.4.
For y,
For the even number of observations, the median value is computed as,
\(\begin{aligned}\tilde y &= average\;of\;{\left( {\frac{n}{2}} \right)^{th}}and\;{\left( {\frac{n}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {\frac{{50}}{2}} \right)^{th}}and\;{\left( {\frac{{50}}{2} + 1} \right)^{th}}\;ordered\;values\\ &= average\;of\;{\left( {25} \right)^{th}}and\;{\left( {26} \right)^{th}}\;ordered\;values\\ &= \frac{{1.5 + 1.7}}{2}\\ &= 1.6\end{aligned}\)
Thus, the median value is 1.6.
Computing the fourths and fourth spread
For ED,
\(\begin{aligned}{l}{n_{smallest}} &= 13\\{n_{{\rm{largest}}}} &= 13\end{aligned}\)
The lower fourth is computed as,
\(\begin{aligned}\frac{{{n_{smallest}} + 1}}{2} &= \frac{{13 + 1}}{2} \\ &= {7^{th}}value \\ \end{aligned} \)
The 7th value of the smallest half is 0.1.
This implies that the lower fourth is 0.1.
The upper fourth is computed as,
\(\begin{aligned}\frac{{{n_{{\rm{largest}}}} + 1}}{2} &= \frac{{13 + 1}}{2}\\ &= {7^{th}}value\end{aligned}\)
The 7th value of the largest half is 2.8.
This implies that the upper fourth is 2.8.
The fourth spread is computed as,
\(\begin{aligned}{f_s} &= {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &= 2.8 - 0.1\\ &= 2.7\end{aligned}\)
Therefore, the fourth spread is 2.7.
or non-ED,
\(\begin{aligned}{l}{n_{smallest}} &= 25\\{n_{{\rm{largest}}}} &= 25\end{aligned}\)
The lower fourth is computed as,
\(\begin{aligned}\frac{{{n_{smallest}} + 1}}{2} &= \frac{{25 + 1}}{2}\\ &= {13^{th}}value\end{aligned}\)
The 13th value of the smallest half is 0.3.
This implies that the lower fourth is 0.3.
The upper fourth is computed as,
\(\begin{aligned}\frac{{{n_{{\rm{largest}}}} + 1}}{2} &= \frac{{25 + 1}}{2}\\ &= {13^{th}}value\end{aligned}\)
The 13th value of the largest half is 7.9.
This implies that the upper fourth is 7.9.
The fourth spread is computed as,
\(\begin{aligned}{f_s} &= {\rm{Upper}}\,{\rm{fourth}} - {\rm{Lower}}\;{\rm{fourth}}\\ &= 7.9 - 0.3\\ &= 7.6\end{aligned}\)
Therefore, the fourth spread is 7.6.
Checking the outliers
b.
Referring to part a,
For ED,
The median value is 0.4.
The lower fourth is 0.1.
The Upper fourth is 2.8.
The fourth spread is 2.7.
For non-ED,
The median value is 1.6.
The lower fourth is 0.3.
The Upper fourth is 7.9.
The fourth spread is 7.6.
Any observation farther than 1.5\({f_s}\) from the closest fourth is an outlier.
An outlier is extreme if it is more than 3\({f_s}\) from the nearest fourth, otherwise, it is mild.
For x,
The calculations are as follows,
\(\begin{aligned}Lower\;fourth - 1.5{f_s} &= 0.1 - \left( {1.5*2.7} \right)\\ &= 0.1 - 4.05\\ &= - 3.95\end{aligned}\)
\(\begin{aligned}Upper\;fourth + 1.5{f_s} &= 2.8 + \left( {1.5*2.7} \right)\\ &= 2.8 + 4.05\\ &= 6.85\end{aligned}\)
It can be observed that there are no values that are less than -3.95.but there are few values that exceeds 6.85; they are, 8.9, 9.2,11.7 and 21.
For extreme outlier,
\(\begin{aligned}Upper\;fourth + 3{f_s} &= 2.8 + \left( {3*2.7} \right)\\ &= 2.8 + 8.1\\ &= 10.9\end{aligned}\)
Therefore, the extreme outliers are 11.7 and 21.
For y,
The calculations are as follows,
\(\begin{aligned}Lower\;fourth - 1.5{f_s} &= 0.3 - \left( {1.5*7.6} \right)\\ < 0\end{aligned}\)
\(\begin{aligned}Upper\;fourth + 1.5{f_s} &= 7.9 + \left( {1.5*7.6} \right)\\ &= 7.9 + 11.4\\ &= 19.3\end{aligned}\)
It can be observed that there are no values that are negative and no values are greater than 19.3.
This implies that are no outliers.
Construction of a comparative boxplot
Referring to parts a and b,
The five-number summary is,
For ED,
The smallest observation is 0.
The median value is 0.4.
The lower fourth is 0.1.
The Upper fourth is 2.8.
The fourth spread is 2.7.
The largest observation is 21.
For non-ED,
The smallest observation is 0.
The median value is 1.6.
The lower fourth is 0.3.
The Upper fourth is 7.9.
The fourth spread is 7.6.
The largest observation is 17.8.
The steps to construct a boxplot are as follows,
1. Compute the values of the five-number summary (smallest value, lower fourth, median, upper fourth, largest value).
2. Construct a line segment from the smallest value to the largest value of the dataset.
3. Construct a rectangular box from the lower fourth to the upper fourth and draw a line in the box at the median value.
The boxplot is represented as,
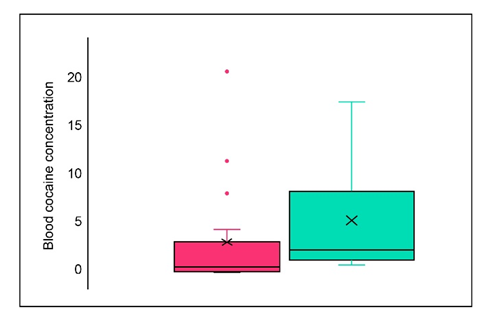
The red-colored boxplot represents ED, and the green-colored boxplot represents non-ED.
The comparison is as follows,
1. There are four outliers for ED and no outliers for non-ED samples.
2. The distribution is positively skewed for both samples.
3. There is less variability in ED than in the non-ED sample.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
