Chapter 3: Q 3.54. (page 105)
Outliers and trimmed means. Some data sets contain outliers, observation that fall well outside the overall pattern of the data(We discuss outliers in more detail in section 3.4) Suppose, for instance that you are interested in the ability o high school algebra student to compute square roots. You decide to give a square root exam to 10 of these students Unfortunately, one of the student had a fight with his girlfriend and cannot concentrate he gets a 0. The 10 score are displayed in increasing order in the following table. The score of 0 is an outlier.

Statisticians have a systematic method for avoiding extreme observation and outliers when they calculated means. They compute trimmed means, in which high and low observation are deleted or "trimmed off" before the mean is calculated . For instance, to compute the 10% trimmed mean of the test score data. we first delete both the bottom 10% and the top 10% of the ordered data. that is,0 and 80. Then we calculated the mean of the remaining data. Thus the10% trimmed mean of the test score data is
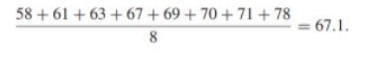
The following table displays a set of score for a 40 question algebra final

Part (a) Do any the score look like outliers?
Part (b) Compute the usual mean of the data.
Part (c) Compute the 5% trimmed mean of the data.
Part (d) Compute the 10% trimmed mean of the data.
Part (e) Compare the means you obtained in parts (b) (d) which of the three provides the best measure of center for the data?
Short Answer
Part (a) 2 and 4 are outliers.
Part (b) 19.25
Part (c) 19.72
Part (d) 20.25
Part (e) 10% trimmed value is better measure of center
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!