Weekly Salaries. In the following table, we repeat the salary data in Data Set II from Example 3.1.

(a) Use Definitions 3.4 and 3.6 on pages 99 and 108, respectively, to obtain the sample mean and sample standard deviation of this (ungrouped) data set.
(b) A frequency distribution for Data Set II, using single-value grouping, is presented in the first two columns of the following table. The third column of the table is for thexf- values, that is, classmark or midpoint (which here is the same as the class) times class frequency. Complete the missing entries in the table and then use the grouped-data formula to obtain the sample mean.
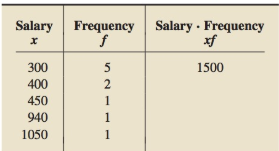
(c) Compare the answers that you obtained for the sample mean in parts (a) and (b). Explain why the grouped-data formula always yields the actual sample mean when the data are grouped by using single-value grouping. (Hint: What does xf represent for each class?)
(d) Construct a table similar to the one in part (b) but with columns for .Use the table and the grouped-data formula to obtain the sample standard deviation.
(e) Compare your answers for the sample standard deviation in parts (a) and (d). Explain why the grouped-data formula always yields the actual sample standard deviation when the data are grouped by using single-value grouping.



