Chapter 12: Q12-44E (page 744)
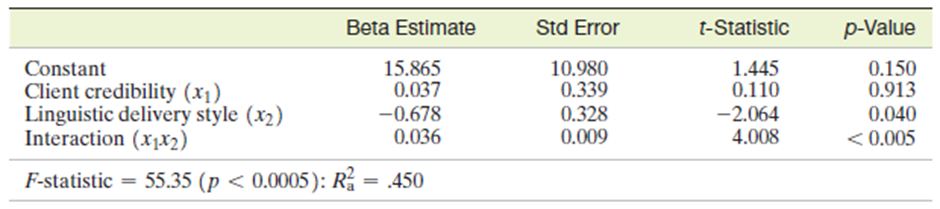
Factors that impact an auditor’s judgment. A study was conducted to determine the effects of linguistic delivery style and client credibility on auditors’ judgments (Advances in Accounting and Behavioural Research, 2004). Two hundred auditors from Big 5 accounting firms were each asked to perform an analytical review of a fictitious client’s financial statement. The researchers gave the auditors different information on the client’s credibility and linguistic delivery style of the client’s explanation. Each auditor then provided an assessment of the likelihood that the client-provided explanation accounted for the fluctuation in the financial statement. The three variables of interest—credibility (x1), linguistic delivery style (x2) , and likelihood (y) —were all measured on a numerical scale. Regression analysis was used to fit the interaction model, . The results are summarized in the table at the bottom of page.
a) Interpret the phrase client credibility and linguistic delivery style interact in the words of the problem.
b) Give the null and alternative hypotheses for testing the overall adequacy of the model.
c) Conduct the test, part b, using the information in the table.
d) Give the null and alternative hypotheses for testing whether client credibility and linguistic delivery style interact.
e) Conduct the test, part d, using the information in the table.
f) The researchers estimated the slope of the likelihood–linguistic delivery style line at a low level of client credibility 1x1 = 222. Obtain this estimate and interpret it in the words of the problem.
g) The researchers also estimated the slope of the likelihood–linguistic delivery style line at a high level of client credibility 1x1 = 462. Obtain this estimate and interpret it in the words of the problem.
Short Answer
a) In the model, variables x1 and x2 are said to have some interaction amongst them indicating that there is a relationship between the two variables which means that the client’s credibility might be related to the linguistic delivery style the client had chosen. This dependency is expressed using the term ‘x1 x2 ’.
b) while Ha At least one of the parameters is non zero
c) At 95% significance level, it can be concluded that
d) The null hypothesis and alternate hypothesis are while
e) At 95% significance level localid="1651179551636" . Hence it can be concluded with enough evidence that x1 and x2do not interact in the model.
f) The slope of the line relating y to x2 when x1 = 22 is 1.47. The positive value denotes a positive relationship amongst the two variables and a low value means that the relation is not so strong.
g) The slope of the line relating y to x2 when x1 = 46 is 2.334. The positive value denotes a positive relationship amongst the two variables and a low value means that the relation is not so strong.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!

