Chapter 10: Q9BSC (page 468)
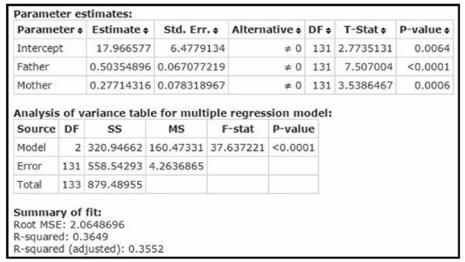
In Exercises 9–12, refer to the accompanying table, which was obtained using the data from 21 cars listed in Data Set 20 “Car Measurements” in Appendix B. The response (y) variable is CITY (fuel consumption in mi/gal). The predictor (x) variables are WT (weight in pounds), DISP (engine displacement in liters), and HWY (highway fuel consumption in mi/gal).
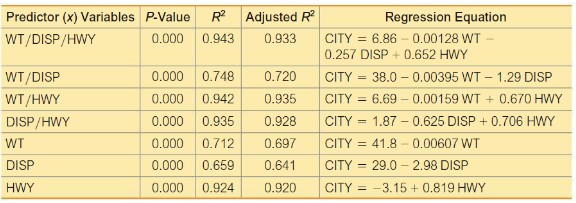
If only one predictor (x) variable is used to predict the city fuel consumption, which single variable is best? Why?
Short Answer
Expert verified
HWY is the best predictor in the single variable study for predicting fuel consumption of the city.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!