Chapter 10: Q17BSC (page 468)
Exercises 13–28 use the same data sets as Exercises 13–28 in Section 10-1. In each case, find the regression equation, letting the first variable be the predictor (x) variable. Find the indicated predicted value by following the prediction procedure summarized in Figure 10-5 on page 493.
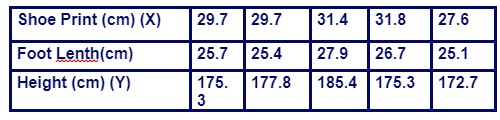
Use the shoe print lengths and heights to find the best predicted height of a male who has a shoe print length of 31.3 cm. Would the result be helpful to police crime scene investigators in trying to describe the male?
Short Answer
The regression equation is\(\hat y = 125 + 1.73x\).
The best-predicted height with a shoe-print length of 31.3 cm will be 177 cm. As the best prediction is made using the mean value, it will not be helpful for the police to trace a male criminal.
Step by step solution
Given information
The given data provides the information of the shoe print (in cm) and the height (in cm), as follows.

State the equation of the regression line
The formula for the estimated regression line is
\(y = {b_0} + {b_1}x\).
Here,
\({b_0}\)is the Y-intercept,
\({b_1}\)is the slope,
\(x\)is the explanatory variable, and
\(\hat y\)is the response variable (predicted value).
Let X denote the shoe print (in cm) and Y denote the height (in cm) of the male.
Compute the slope and intercept
The calculations required to compute the slope and intercept are as follows.
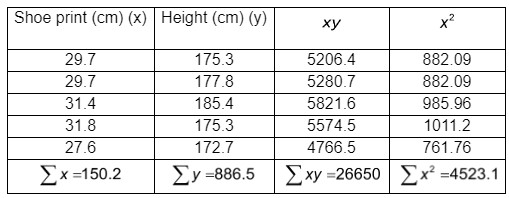
The sample size is \(\left( n \right) = 5\).
The slope is computed as
\(\begin{array}{c}{b_1} = \frac{{n\left( {\sum {xy} } \right) - \left( {\sum x } \right)\left( {\sum y } \right)}}{{n\left( {\sum {{x^2}} } \right) - {{\left( {\sum x } \right)}^2}}}\\ = \frac{{5 \times 26650 - 150.2 \times 886.5}}{{5 \times 4523.1 - {{150.2}^2}}}\\ = 1.73\end{array}\).
The intercept is computed as
\(\begin{array}{c}{b_0} = \frac{{\left( {\sum y } \right)\left( {\sum {{x^2}} } \right) - \left( {\sum x } \right)\left( {\sum {xy} } \right)}}{{n\left( {\sum {{x^2}} } \right) - {{\left( {\sum x } \right)}^2}}}\\ = \frac{{886.5 \times 4523.1 - 150.2 \times 26650}}{{5 \times 4523.1 - {{150.2}^2}}}\\ = 125.4\end{array}\).
So, the estimated regression equation is
\(\begin{array}{c}\hat y = {b_0} + {b_1}x\\ = 125 + 1.73x\end{array}\).
Checking the model
Refer to exercise 17 of section 10-1 for the following result.
1) The scatter plot does not show an approximate linear relationship between the variables.
2) The P-value is 0.294.
As theP-value is greater than the level of significance (0.05), the null hypothesis is failed to be rejected.
Therefore, the correlation is not significant.
Referring to figure 10-5, the criteria for a good regression model are not satisfied.
The best-predicted value of a variable is the sample mean of the response variable.
Compute the prediction
The best-predicted height of a male who has a shoe-print length of 31.3 cm is computed as follows.
The sample mean:
\(\begin{array}{c}\bar y = \frac{{\sum y }}{n}\\ = \frac{{\left( {175.3 + 177.8 + ... + 172.7} \right)}}{5}\\ = 177.3\end{array}\).
Therefore, the best-predicted height of a male who has a shoe-print length of 31.3 cm will be approximately 177 cm.
It will not be helpful to the police in trying to obtain a description of the male because the resultant value is obtained from a bad regression model.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!