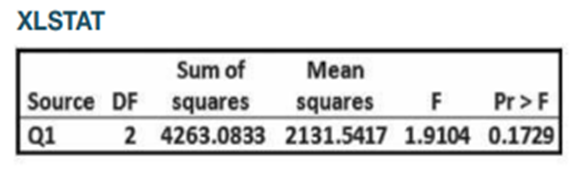
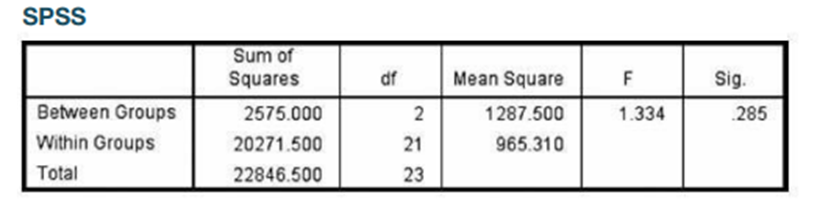
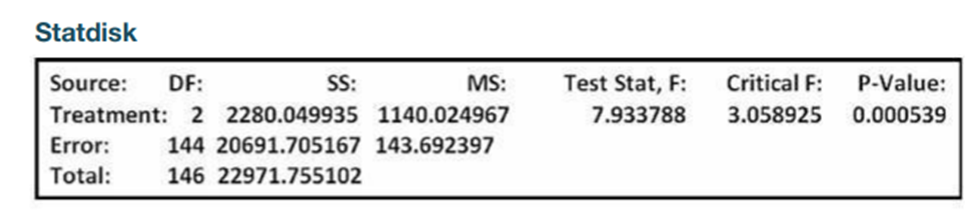
Chapter 12: Q8CRE (page 566)
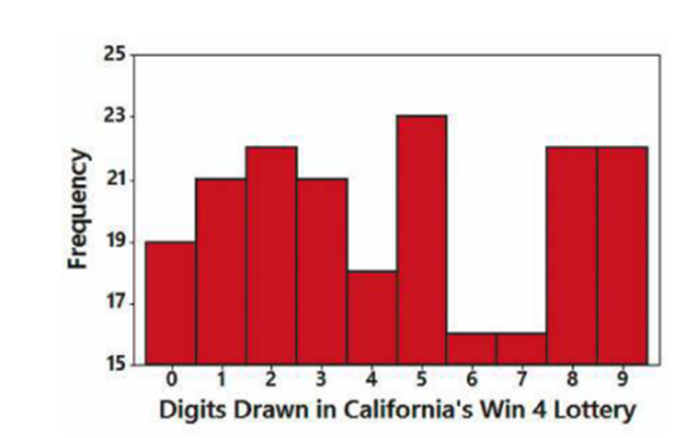
Win 4 Lottery Shown below is a histogram of digits selected in California’s Win 4 lottery. Each drawing involves the random selection (with replacement) of four digits between 0 and 9 inclusive.
a. What is fundamentally wrong with the graph?
b. Does the display depict a normal distribution? Why or why not? What should be the shape of the histogram?
c. Identify the frequencies, then test the claim that the digits are selected from a population in which the digits are all equally likely. Is there a problem with the lottery?
Short Answer
a. The vertical axis does not start from 0, which makes the graph deceptive.
b. The graph is not normally distributed, and the shape is expected to be rectangular.
c. The frequencies are tabulated below. Also, the test proves that the digits are taken from a population where each digit is equally likely.
Digits | Frequency |
0 | 19 |
1 | 21 |
2 | 22 |
3 | 21 |
4 | 18 |
5 | 23 |
6 | 16 |
7 | 16 |
8 | 22 |
9 | 22 |
No, there is no problem with the lottery as the distribution of digits is even.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!