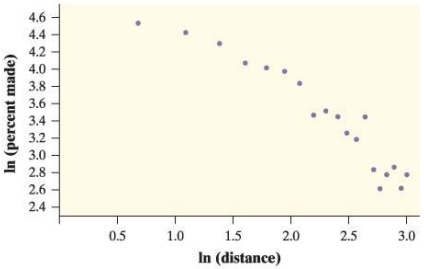
Chapter 12: Q. R12.1 (page 822)
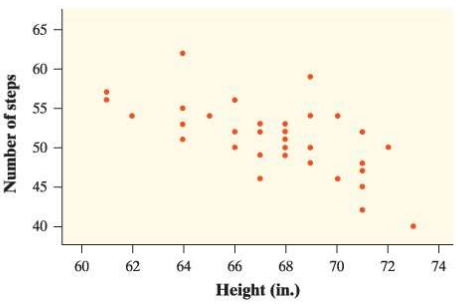
Do taller students require fewer steps to walk a fixed distance? The scatterplot shows the relationship between x=height (in inches) and y=number of steps required to walk the length of a school hallway for a random sample of 36 students at a high school.
A least-squares regression analysis was performed on the data. Here is some computer output from the analysis

a. Describe what the scatterplot tells you about the relationship between height and the number of steps.
b. What is the equation of the least-squares regression line? Define any variables you use.
c. Identify the value of each of the following from the computer output. Then provide an interpretation of each value.
i.
ii.
iii. s
iv.
Short Answer
(a) There are no outliers in the relationship between height and the number of steps, which is moderately strong, negative, and linear.
(b)
(c)
Step by step solution
Part (a) Step 1: Given information
The given data is

Part (a) Step 2: Explanation
A study was done to see if taller students needed fewer steps to go a certain distance. The scatterplot in the question depicts the link between height and the number of steps needed to walk down the school corridor.
As a result, we can see from the scatterplot that,
Because the scatterplot's pattern slopes downhill, the scatterplot's orientation is negative. Because there is no considerable curvature in the scatterplot, it takes the form of a linear graph. The scatterplot's strength is reasonably strong since the points in the scatterplot are not too close together but also not too far away.
The odd aspect is that no outliers occur since no points depart significantly from the pattern in the other points.
Part (b) Step 1: Given information
The given data is

Part (b) Step 2: Explanation
A study was done to see if taller students needed fewer steps to go a certain distance. The scatterplot in the question depicts the link between height and the number of steps needed to walk down the school corridor. The least square regression line's general equation is:
As a result of the computer output, we can see that the constant estimate is presented in the row "Constant" and the column "Coef" as:
And the slope estimate is supplied in the row "Height" and the column "Coef" as follows:
Now we'll plug the above values into the regression line's equation, where represents the height and indicates the number of steps.
role="math" localid="1654242650804"
Part (c) Step 1: Given information
The given data is

Part (c) Step 2: Explanation
A study was done to see if taller students needed fewer steps to go a certain distance. The scatterplot in the question depicts the link between height and the number of steps needed to walk down the school corridor. Now we must determine and interpret the value:
i) In the row "Constant" and the column "Coef" of the given computer output, the intercept is presented as:
When is zero, the intercept indicates the average value. When the height is 0 inches, the average number of steps is steps.
ii. : In the row "Height" and the column "Coef" of the given computer output, the slope is given as:
The slope shows how much y has increased or decreased per unit of . As a result, the average number of steps is less than the actual number of steps.
iii. : the standard error of the estimate $s$ is supplied in the computer output after " " as:
As a result, the anticipated number of steps differs by steps on average from the actual number of steps.
iv. In the row "Height" and the column "SE Coef" of the given computer output, the standard error of the slope is presented as:
As a result, the slope of the sample regression line differs from the true population regression line by on average.
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!