Chapter 12: 122E (page 802)
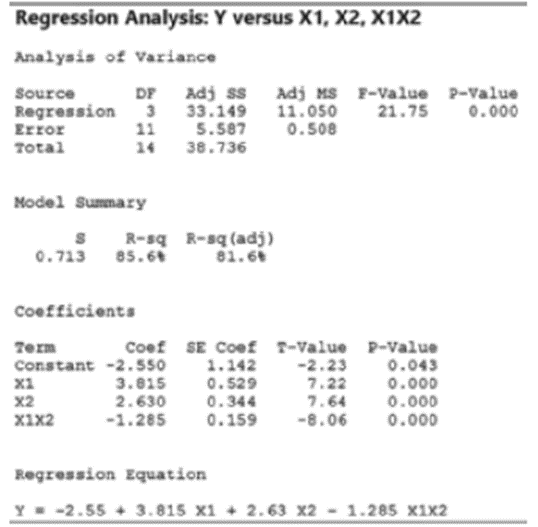
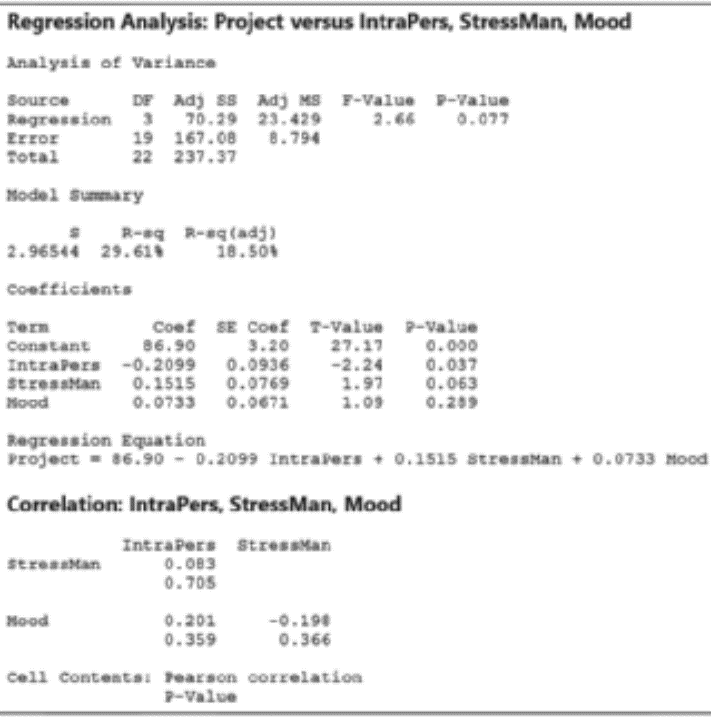
Emotional intelligence and team performance. Refer to the Engineering Project Organizational Journal (Vol. 3, 2013) study of the relationship between emotional intelligence of individual team members and their performance during an engineering project, Exercise 12.33 (p. 733). Using data on n = 23 teams, you fit a first-order model for mean project score (y) as a function of range of interpersonal scores (x1), range of stress management scores (x2), and range of mood scores (x3). The regression results, as well as a correlation matrix for the independent variables, are displayed in the accompanying Minitab printout. Do you detect any signs of multicollinearity in the data? [Note: The researchers expect the linear relationship between project score and each independent variable to be negative for range of interpersonal scores and positive for both range of stress management scores and mood scores.]
Short Answer
Since the r coefficient values for all three parameters are less than 0.2, it can be concluded that there is a low level of multicollinearity amongst the variables. And the signs of β values for all three independent variables are as expected by the researchers
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!