Chapter 12: Q7SE (page 850)
In Sec. 10.2, we discussed \({\chi ^2}\) goodness-of-fit tests for composite hypotheses. These tests required computing M.L.E.'s based on the numbers of observations that fell into the different intervals used for the test. Suppose instead that we use the M.L.E.'s based on the original observations. In this case, we claimed that the asymptotic distribution of the \({x^2}\) test statistic was somewhere between two different \({\chi ^2}\) distributions. We can use simulation to better approximate the distribution of the test statistic. In this exercise, assume that we are trying to test the same hypotheses as in Example 10.2.5, although the methods will apply in all such cases.
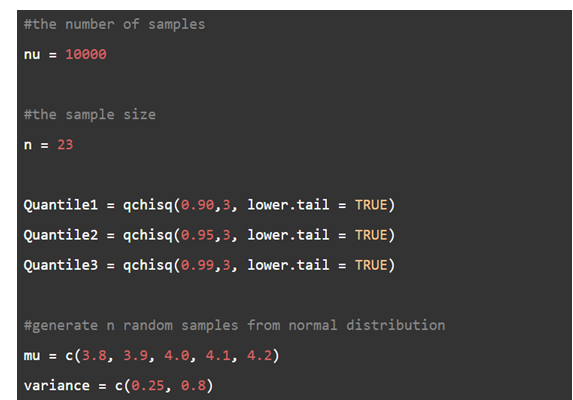
a. Simulate \(v = 1000\) samples of size \(n = 23\) from each of 10 different normal distributions. Let the normal distributions have means of \(3.8,3.9,4.0,4.1,\) and \(4.2\) Let the distributions have variances of 0.25 and 0.8. Use all 10 combinations of mean and variance. For each simulated sample, compute the \({\chi ^2}\) statistic Q using the usual M.L.E.'s of \(\mu \) , and \({\sigma ^2}.\) For each of the 10 normal distributions, estimate the 0.9,0.95, and 0.99 quantiles of the distribution of Q.
b. Do the quantiles change much as the distribution of the data changes?
c. Consider the test that rejects the null hypothesis if \(Q \ge 5.2.\) Use simulation to estimate the power function of this test at the following alternative: For each \(i,\left( {{X_i} - 3.912} \right)/0.5\) has the t distribution with five degrees of freedom.
Short Answer
(a) There are a total of 30 estimates.
(b) There are changes. They do not seem to be huge.
(c) Varies around 0.0357.
Step by step solution
To find the sample and distribution of Q
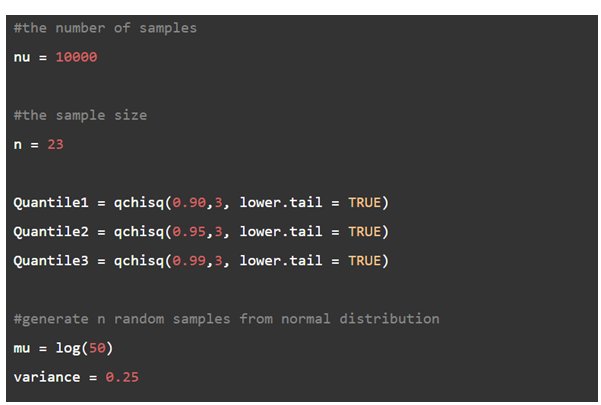
- Follow the assumptions in the exercise. First, note that there should be\(\nu = 10000\)normal distribution samples of size n=23 with mean\(log(50)\)and the standard deviation of\(\sqrt {0.25} \)under the null hypothesis. Hence,\(\mu = 3.921,\)and\({\sigma ^2} = 0.25.\)
Another assumption is that the generated samples are taken from the 10 different normal distributions from all possible combinations of means and standard deviations given in the exercise. For each of the 10 combinations, there should be 3 different quantiles estimates, that is,\(3 \times 10 = 30\)in total.
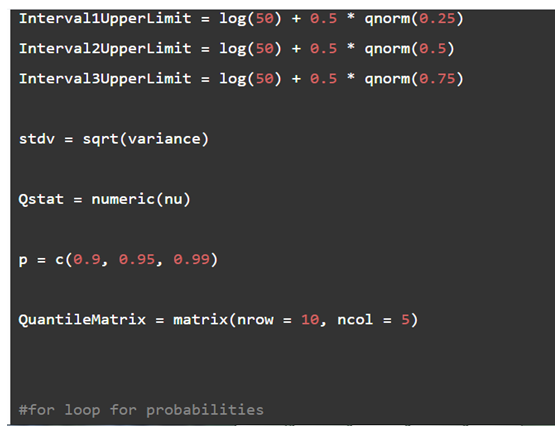
The number of intervals should not exceed 5, so\(5 - 1 = 4\) it will be used in this simulation. The intervals depend on the probability of the distribution under the null hypothesis, which is the mentioned normal distribution. The upper limit of the first interval is
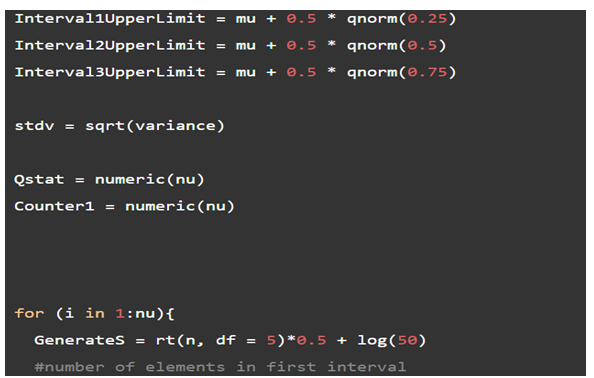
\(U{L_1} = \mu + 0.5 \times {\Phi ^{ - 1}}(0.25) = 3.192 + 0.5 \times ( - 0.674) = 3.575\)
where\(P\left( {Z < - 0.674} \right) = 0.25.\)
This way, the probability that the observation falls in the interval\(( - \infty ,3.575)\)is 0.25. The other 3 intervals shall have the exact probabilities and are computed using\({\Phi ^{ - 1}}(0.5)\)\({\Phi ^{ - 1}}(0.75)\)instead of\({\Phi ^{ - 1}}(0.25)\)
\(\begin{aligned}{c}U{L_2} = \mu + 0.5 \times {\Phi ^{ - 1}}(0.5) = 3.192 + 0.5 \times 0 = 3.912U{L_3} \\ = \mu + 0.5 \times {\Phi ^{ - 1}}(0.75) = 3.192 + 0.5 \times 0.674 = 4.249\end{aligned}\)
Then, the\({\chi ^2}\)statistic value is computed using
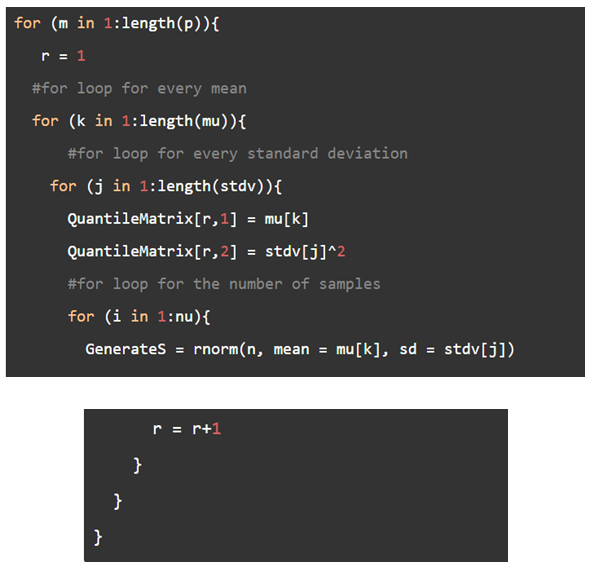
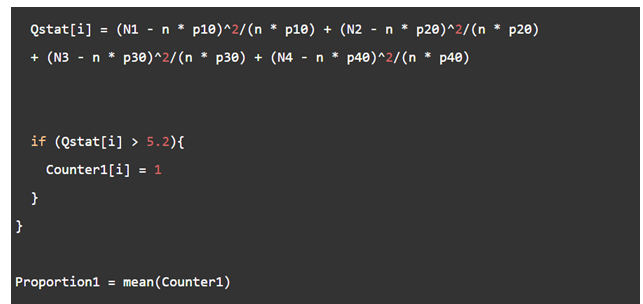
\(Q = \sum\limits_{i = 1}^k {\frac{{{{\left( {{N_i} - np_i^0} \right)}^2}}}{{np_i^0}}} \)
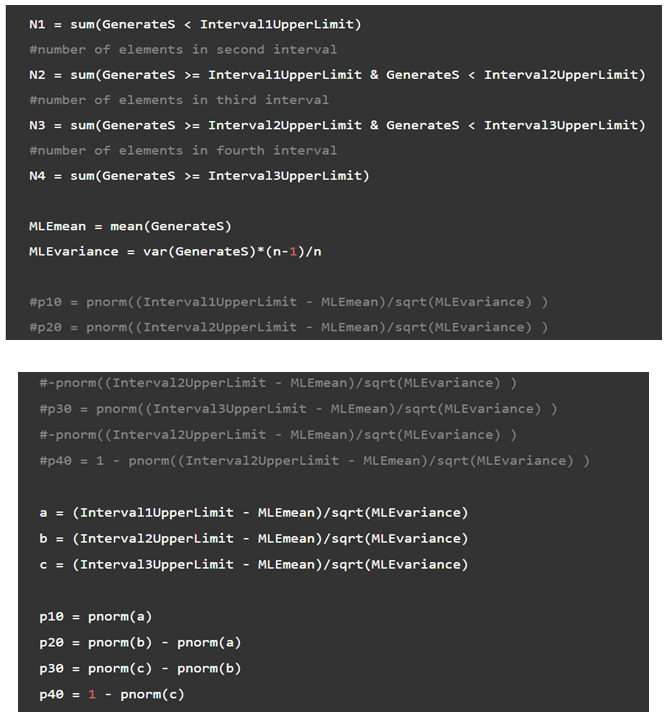
Where, in this case,\({N_i},i = 1,2,3,4\)are the number of observations that fall in the\({i^{th }}\)interval, n=23, and\(p_i^0\)will be calculated using the maximum likelihood estimates of the generated samples. For example, if\(\hat \mu \)and\({\hat \sigma ^2}\)are the MLE of the parameters\(\mu \)and\(\sigma ,\)then the probabilities are given/estimated by
\(\begin{aligned}{l}\hat p_1^0 = \Phi \;\;\;{\kern 1pt} \frac{{U{L_1} - \hat \mu }}{{\hat \sigma }}\\\hat p_2^0 = \Phi \;\;\;{\kern 1pt} \frac{{U{L_2} - \hat \mu }}{{\hat \sigma }} - \Phi \frac{{U{L_1} - \hat \mu }}{{\hat \sigma }}\\\hat p_3^0 = \Phi \;\;\;{\kern 1pt} \frac{{U{L_3} - \hat \mu }}{{\hat \sigma }} - \Phi \frac{{U{L_2} - \hat \mu }}{{\hat \sigma }}\\\hat p_4^0 = 1 - \Phi \;\;\;{\kern 1pt} \frac{{U{L_3} - \hat \mu }}{{\hat \sigma }}\end{aligned}\)
Then, use the\({\chi ^2}\)statistic given above. After computing the Q statistic values, order them and take the\(n \times {p^{th }}\)value where\(p \in \{ 0.9,0.95,0.99\} \)to obtain the estimate of the quantile of the distribution.
The resulting estimates are given in the following table. As mentioned, there are a total of 30 estimates of the quantiles. The "Quantile Matrix" from the code gives the desired result. The code in RStudio is given below.
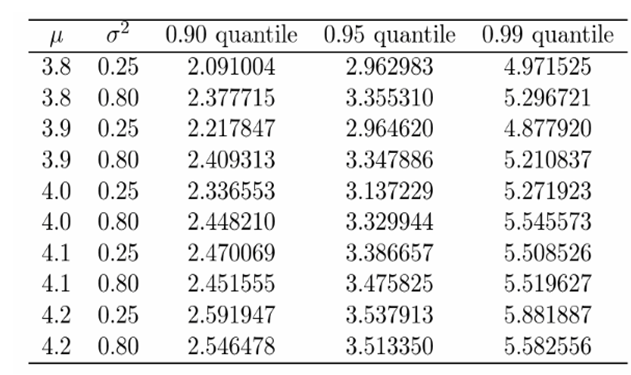

To find the estimated probability.
There are changes. However, they do not seem to be huge.
Five degrees of freedom
Generate a student t distribution with 5 degrees of freedom, as given in the exercise. The estimated probability using the code below is around \(0.0357.\)
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!
