Chapter 2: Q. 2.14 (page 90)
Find the interquartile range for the following two data sets and compare them.
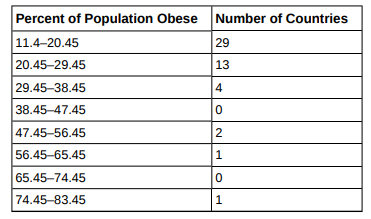
Test Scores for Class A
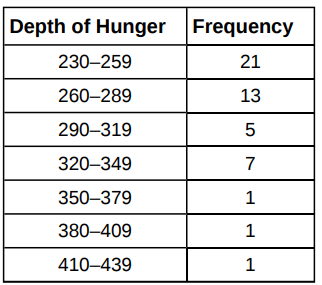
Test Scores for Class B
Short Answer
Expert verified
We can tell whether data set is wider or more dispersed based on the IQR.
In this case, we may argue that class B is larger than class A.
Step by step solution
Over 30 million students worldwide already upgrade their learning with 91Ӱ��!